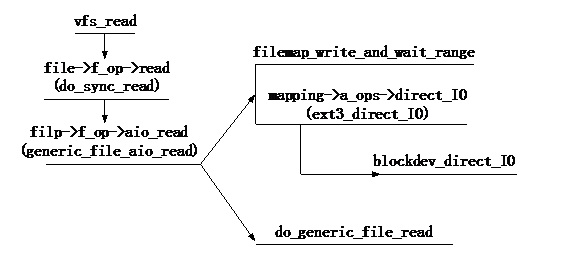
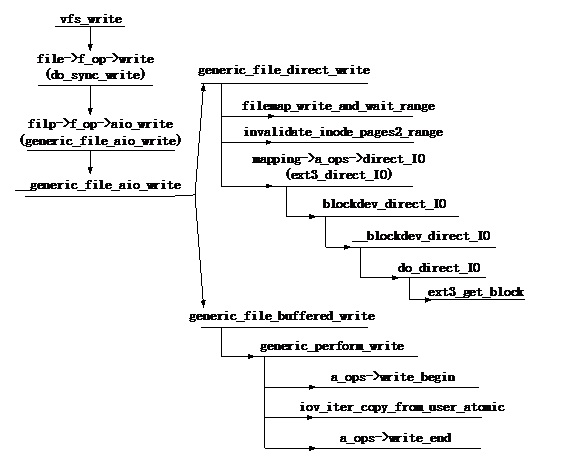
ssize_t __generic_file_aio_write(struct kiocb *iocb, conststruct iovec *iov, unsignedlong nr_segs, loff_t *ppos) { structfile *file = iocb->ki_filp; /* 获取address space映射信息 */ structaddress_space * mapping = file->f_mapping; size_t ocount; /* original count */ size_t count; /* after file limit checks */ structinode *inode = mapping->host; /* 获取文件inode索引节点 */ loff_t pos; ssize_t written; ssize_t err; ocount = 0; /* 检验数据区域是否存在问题,数据由iov数据结构管理 */ err = generic_segment_checks(iov, &nr_segs, &ocount, VERIFY_READ); if (err) return err; /* ocount为可以写入的数据长度 */ count = ocount; pos = *ppos; vfs_check_frozen(inode->i_sb, SB_FREEZE_WRITE); /* We can write back this queue in page reclaim */ current->backing_dev_info = mapping->backing_dev_info; written = 0; /* 边界检查,需要判断写入数据是否超界、小文件边界检查以及设备是否是read-only。如果超界,那么降低写入数据长度 */ err = generic_write_checks(file, &pos, &count, S_ISBLK(inode->i_mode)); if (err) goto out; /* count为实际可以写入的数据长度,如果写入数据长度为0,直接结束 */ if (count == 0) goto out; err = file_remove_suid(file); if (err) goto out; file_update_time(file); /* coalesce the iovecs and go direct-to-BIO for O_DIRECT */ if (unlikely(file->f_flags & O_DIRECT)) { /* Direct IO操作模式,该模式会bypass Page Cache,直接将数据写入磁盘设备 */ loff_t endbyte; ssize_t written_buffered; /* 将对应page cache无效掉,然后将数据直接写入磁盘 */ written = generic_file_direct_write(iocb, iov, &nr_segs, pos, ppos, count, ocount); if (written < 0 || written == count) /* 所有数据已经写入磁盘,正确返回 */ goto out; /* * direct-io write to a hole: fall through to buffered I/O * for completing the rest of the request. */ pos += written; count -= written; /* 有些请求由于没有和块大小(通常为512字节)对齐,那么将无法正确完成direct-io操作。在__blockdev_direct_IO 函数中会检查逻辑地址是否和块大小对齐,__blockdev_direct_IO无法处理不对齐的请求。另外,在ext3逻辑地址和物理块地址映射操作函数ext3_get_block返回失败时,无法完成buffer_head的映射,那么request请求也将无法得到正确处理。所有没有得到处理的请求通过 buffer写的方式得到处理。从这点来看,direct_io并没有完全bypass page cache,在有些情况下是一种写无效模式。generic_file_buffered_write函数完成buffer写,将数据直接写入page cache */ written_buffered = generic_file_buffered_write(iocb, iov, nr_segs, pos, ppos, count, written); /* * If generic_file_buffered_write() retuned a synchronous error * then we want to return the number of bytes which were * direct-written, or the error code if that was zero. Note * that this differs from normal direct-io semantics, which * will return -EFOO even if some bytes were written. */ if (written_buffered < 0) { /* 如果page cache写失败,那么返回写成功的数据长度 */ err = written_buffered; goto out; } /* * We need to ensure that the page cache pages are written to * disk and invalidated to preserve the expected O_DIRECT * semantics. */ endbyte = pos + written_buffered - written - 1; /* 将page cache中的数据同步到磁盘 */ err = filemap_write_and_wait_range(file->f_mapping, pos, endbyte); if (err == 0) { written = written_buffered; /* 将page cache无效掉,保证下次读操作从磁盘获取数据 */ invalidate_mapping_pages(mapping, pos >> PAGE_CACHE_SHIFT, endbyte >> PAGE_CACHE_SHIFT); } else { /* * We don't know how much we wrote, so just return * the number of bytes which were direct-written */ } } else { /* 将数据写入page cache。绝大多数的ext3写操作都会采用page cache写方式,通过后台writeback线程将page cache同步到硬盘 */ written = generic_file_buffered_write(iocb, iov, nr_segs, pos, ppos, count, written); } out: current->backing_dev_info = NULL; return written ? written : err; }
ssize_t generic_file_direct_write(struct kiocb *iocb, conststruct iovec *iov, unsignedlong *nr_segs, loff_t pos, loff_t *ppos, size_t count, size_t ocount) { structfile *file = iocb->ki_filp; structaddress_space *mapping = file->f_mapping; structinode *inode = mapping->host; ssize_t written; size_t write_len; pgoff_t end; if (count != ocount) *nr_segs = iov_shorten((struct iovec *)iov, *nr_segs, count); write_len = iov_length(iov, *nr_segs); end = (pos + write_len - 1) >> PAGE_CACHE_SHIFT; /* 将对应区域page cache中的新数据页刷新到设备,这个操作是同步的 */ written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1); if (written) goto out; /* * After a write we want buffered reads to be sure to go to disk to get * the new data. We invalidate clean cached page from the region we're * about to write. We do this *before* the write so that we can return * without clobbering -EIOCBQUEUED from ->direct_IO(). */ /* 将page cache对应page 缓存无效掉,这样可以保证后继的读操作能从磁盘获取最新数据 */ if (mapping->nrpages) { /* 无效对应的page缓存 */ written = invalidate_inode_pages2_range(mapping, pos >> PAGE_CACHE_SHIFT, end); /* * If a page can not be invalidated, return 0 to fall back * to buffered write. */ if (written) { if (written == -EBUSY) return0; goto out; } } /* 调用ext3文件系统的direct io方法,将数据写入磁盘 */ written = mapping->a_ops->direct_IO(WRITE, iocb, iov, pos, *nr_segs); /* * Finally, try again to invalidate clean pages which might have been * cached by non-direct readahead, or faulted in by get_user_pages() * if the source of the write was an mmap'ed region of the file * we're writing. Either one is a pretty crazy thing to do, * so we don't support it 100%. If this invalidation * fails, tough, the write still worked... */ /* 再次无效掉由于预读操作导致的对应地址的page cache缓存页 */ if (mapping->nrpages) { invalidate_inode_pages2_range(mapping, pos >> PAGE_CACHE_SHIFT, end); } if (written > 0) { pos += written; if (pos > i_size_read(inode) && !S_ISBLK(inode->i_mode)) { i_size_write(inode, pos); mark_inode_dirty(inode); } *ppos = pos; } out: return written; }
staticssize_tgeneric_perform_write(struct file *file, struct iov_iter *i, loff_t pos) { structaddress_space *mapping = file->f_mapping; conststructaddress_space_operations *a_ops = mapping->a_ops; /* 映射处理函数集 */ long status = 0; ssize_t written = 0; unsignedint flags = 0; /* * Copies from kernel address space cannot fail (NFSD is a big user). */ if (segment_eq(get_fs(), KERNEL_DS)) flags |= AOP_FLAG_UNINTERRUPTIBLE; do { structpage *page; unsignedlong offset; /* Offset into pagecache page */ unsignedlong bytes; /* Bytes to write to page */ size_t copied; /* Bytes copied from user */ void *fsdata; offset = (pos & (PAGE_CACHE_SIZE - 1)); bytes = min_t(unsignedlong, PAGE_CACHE_SIZE - offset, iov_iter_count(i)); again: /* * Bring in the user page that we will copy from _first_. * Otherwise there's a nasty deadlock on copying from the * same page as we're writing to, without it being marked * up-to-date. * * Not only is this an optimisation, but it is also required * to check that the address is actually valid, when atomic * usercopies are used, below. */ if (unlikely(iov_iter_fault_in_readable(i, bytes))) { status = -EFAULT; break; } /* 调用ext3中的write_begin函数(inode.c中)ext3_write_begin, 如果写入的page页不存在,那么ext3_write_begin会创建一个Page页,然后从硬盘中读入相应的数据 */ status = a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata); if (unlikely(status)) break; if (mapping_writably_mapped(mapping)) flush_dcache_page(page); pagefault_disable(); /* 将数据拷贝到page cache中 */ copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes); pagefault_enable(); flush_dcache_page(page); mark_page_accessed(page); /* 调用ext3的write_end函数(inode.c中),写完数据之后会将page页标识为dirty,后台writeback线程会将dirty page刷新到设备 */ status = a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata); if (unlikely(status < 0)) break; copied = status; cond_resched(); iov_iter_advance(i, copied); if (unlikely(copied == 0)) { /* * If we were unable to copy any data at all, we must * fall back to a single segment length write. * * If we didn't fallback here, we could livelock * because not all segments in the iov can be copied at * once without a pagefault. */ bytes = min_t(unsignedlong, PAGE_CACHE_SIZE - offset, iov_iter_single_seg_count(i)); goto again; } pos += copied; written += copied; balance_dirty_pages_ratelimited(mapping); if (fatal_signal_pending(current)) { status = -EINTR; break; } } while (iov_iter_count(i)); return written ? written : status; }