1 | mkdir riscv_build |
上述默认为动态编译
如果需要静态编译
1 | make menuconfig O=riscv_build |
融合动态库
1 | riscv_build/_install 为 busybox 等生成的目录 |
生成 cpiogz 最终文件
1 | 把 install.sh 拷过来放到 riscv_build下 |
install.sh 脚本内容
1 | !/bin/bash |
1 | mkdir riscv_build |
1 | make menuconfig O=riscv_build |
1 | riscv_build/_install 为 busybox 等生成的目录 |
1 | 把 install.sh 拷过来放到 riscv_build下 |
1 | !/bin/bash |
https://github.com/mit-pdos/xv6-riscv/
一个简单,类UNIX的 MIT(麻省理工) 教学用操作系统
Xv6内核提供了Unix内核传统上提供的服务和系统调用的子集
| 系统调用 | 描述 |
|---|---|
int fork() |
创建一个进程,返回子进程的PID |
int exit(int status) |
终止当前进程,并将状态报告给wait()函数。无返回 |
int wait(int *status) |
等待一个子进程退出; 将退出状态存入*status; 返回子进程PID。 |
int kill(int pid) |
终止对应PID的进程,返回0,或返回-1表示错误 |
int getpid() |
返回当前进程的PID |
int sleep(int n) |
暂停n个时钟节拍 |
int exec(char *file, char *argv[]) |
加载一个文件并使用参数执行它; 只有在出错时才返回 |
char *sbrk(int n) |
按n 字节增长进程的内存。返回新内存的开始 |
int open(char *file, int flags) |
打开一个文件;flags表示read/write;返回一个fd(文件描述符) |
int write(int fd, char *buf, int n) |
从buf 写n 个字节到文件描述符fd; 返回n |
int read(int fd, char *buf, int n) |
将n 个字节读入buf;返回读取的字节数;如果文件结束,返回0 |
int close(int fd) |
释放打开的文件fd |
int dup(int fd) |
返回一个新的文件描述符,指向与fd 相同的文件 |
int pipe(int p[]) |
创建一个管道,把read/write文件描述符放在p[0]和p[1]中 |
int chdir(char *dir) |
改变当前的工作目录 |
int mkdir(char *dir) |
创建一个新目录 |
int mknod(char *file, int, int) |
创建一个设备文件 |
int fstat(int fd, struct stat *st) |
将打开文件fd的信息放入*st |
int stat(char *file, struct stat *st) |
将指定名称的文件信息放入*st |
int link(char *file1, char *file2) |
为文件file1创建另一个名称(file2) |
int unlink(char *file) |
删除一个文件 |
用户态的基础接口
提供了一个精简版的文件系统, 支持ramdisk, 支持文件读写
可改code, 将用户态程序打包进文件系统, 将文件系统镜像融入到 kernel, 使之成为 kernel .rodata段的内容, 作为ramdisk使用
不依赖加载器, 可以将用户态应用程序和 little kernel 打包到一起
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
经过下面文章的介绍,我们已经知道cache的基本工作原理。
Cache的基本原理 - 知乎
但是,我们一直避开了一个关键问题。我们都知道cache控制器根据地址查找判断是否命中,这里的地址究竟是虚拟地址(virtual address,VA)还是物理地址(physical address,PA)?我们应该清楚CPU发出对某个地址的数据访问,这个地址其实是虚拟地址,虚拟地址经过MMU转换成物理地址,最终从这个物理地址读取数据。因此cache的硬件设计既可以采用虚拟地址也可以采用物理地址甚至是取两者地址部分组合作为查找cache的依据。
我们首先介绍的是虚拟高速缓存,这种cache硬件设计简单。在cache诞生之初,大部分的处理器都使用这种方式。虚拟高速缓存以虚拟地址作为查找对象。如下图所示。

虚拟地址直接送到cache控制器,如果cache hit。直接从cache中返回数据给CPU。如果cache miss,则把虚拟地址发往MMU,经过MMU转换成物理地址,根据物理地址从主存(main memory)读取数据。由于我们根据虚拟地址查找高速缓存,所以我们是用虚拟地址中部分位域作为索引(index),找到对应的的cacheline。然后根据虚拟地址中部分位域作为标记(tag)来判断cache是否命中。因此,我们针对这种index和tag都取自虚拟地址的高速缓存称为虚拟高速缓存,简称VIVT(Virtually Indexed Virtually Tagged)。另外,我们复习下cache控制器查找数据以及判断是否命中的规则:通过index查找对应的cacheline,通过tag判断是否命中cache。 虚拟高速缓存的优点是不需要每次读取或者写入操作的时候把虚拟地址经过MMU转换为物理地址,这在一定的程度上提升了访问cache的速度,毕竟MMU转换虚拟地址需要时间。同时硬件设计也更加简单。但是,正是使用了虚拟地址作为tag,所以引入很多软件使用上的问题。 操作系统在管理高速缓存正确工作的过程中,主要会面临两个问题。歧义(ambiguity)和别名(alias)。为了保证系统的正确工作,操作系统负责避免出现歧义和别名。
歧义是指不同的数据在cache中具有相同的tag和index。cache控制器判断是否命中cache的依据就是tag和index,因此这种情况下,cache控制器根本没办法区分不同的数据。这就产生了歧义。什么情况下发生歧义呢?我们知道不同的物理地址存储不同的数据,只要相同的虚拟地址映射不同的物理地址就会出现歧义。例如两个互不相干的进程,就可能出现相同的虚拟地址映射不同的物理地址。假设A进程虚拟地址0x4000映射物理地址0x2000。B进程虚拟地址0x4000映射物理地址0x3000。当A进程运行时,访问0x4000地址会将物理地址0x2000的数据加载到cacheline中。当A进程切换到B进程的时候,B进程访问0x4000会怎样?当然是会cache hit,此时B进程就访问了错误的数据,B进程本来想得到物理地址0x3000对应的数据,但是却由于cache hit得到了物理地址0x2000的数据。操作系统如何避免歧义的发生呢?当我们切换进程的时候,可以选择flush所有的cache。
flush cache操作有两种:
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
对于没有接触过底层技术的朋友来说,或许从未听说过cache。毕竟cache的存在对程序员来说是透明的。在接触cache之前,先为你准备段code分析。
1 | int arr[10][128]; |
如果你曾经学习过C/C++语言,这段code自然不会陌生。如此简单的将arr数组所有元素置1。 你有没有想过这段code还有下面的一种写法。
1 | int arr[10][128]; |
功能完全一样,但是我们一直在重复着第一种写法(或许很多的书中也是建议这么编码),你是否想过这其中的缘由?文章的主角是cache,所以你一定猜到了答案。那么cache是如何影响这2段code的呢?
在思考为什么需要cache之前,我们首先先来思考另一个问题:我们的程序是如何运行起来的?
我们应该知道程序是运行在 RAM之中,RAM 就是我们常说的DDR(例如: DDR3、DDR4等)。我们称之为main memory(主存)。当我们需要运行一个进程的时候,首先会从磁盘设备(例如,eMMC、UFS、SSD等)中将可执行程序load到主存中,然后开始执行。在CPU内部存在一堆的通用寄存器(register)。如果CPU需要将一个变量(假设地址是A)加1,一般分为以下3个步骤:
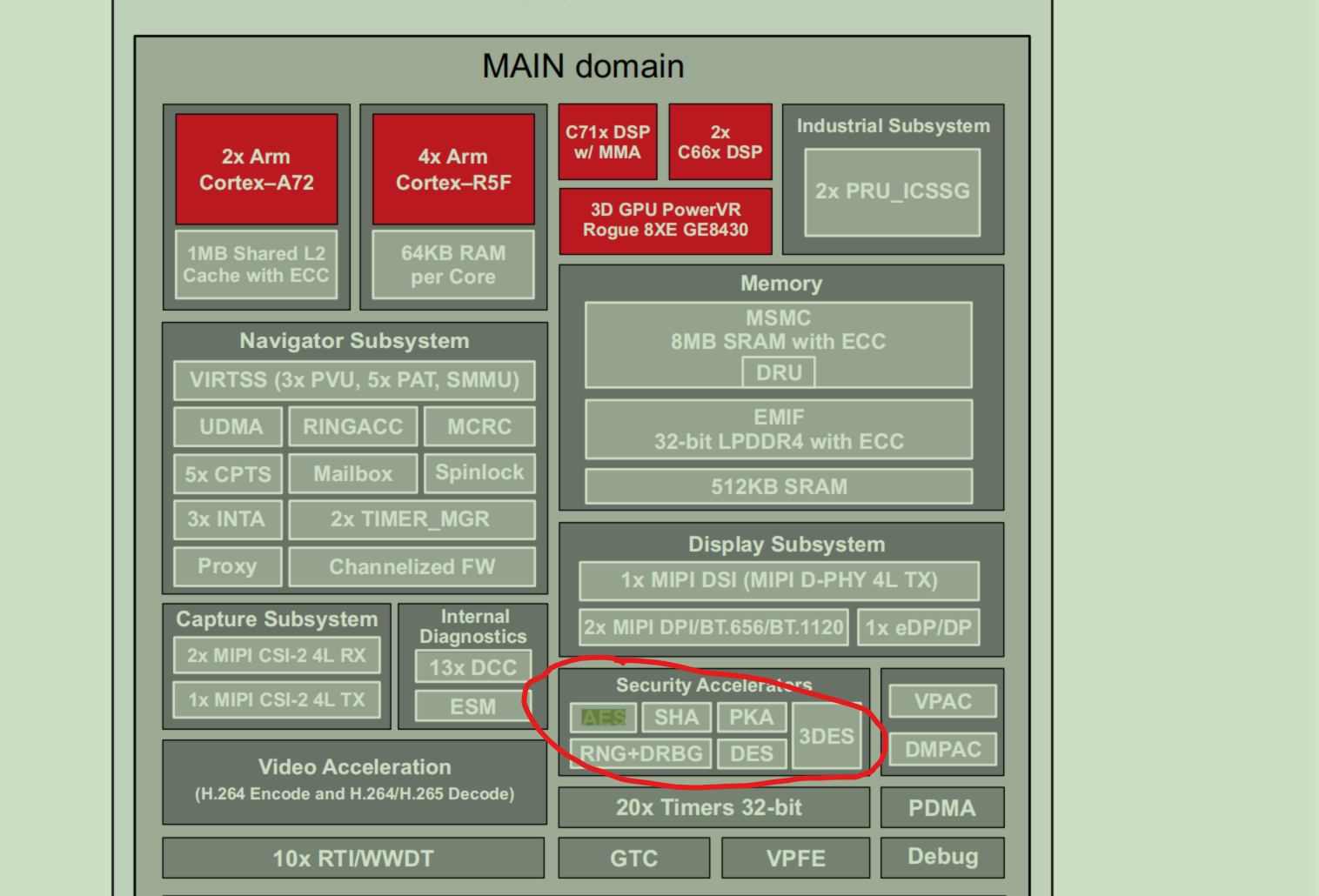
加密硬件加速器 – 带 ECC 的 PKA、AES、SHA、 RNG、DES 和 3DES
Asymmetrische Kryptografie: RSA und ECC-Funktionen
• Hash-Funktionen: Message Digest Algorithm (MD5), SHA1 und SHA2-224/256/384/512
• Symmetrische Kryptografie-Funktionen: AES-128/192/256
• Hardware-TRNG-Modul mit Nachbearbeitung für einen deterministischen Zufallsbitgenerator (DRBG)

Main components of the DMSC are:
•Arm Cortex-M3 processor core (ARMv7-M architecture profile)
•160 KB ROM to allow boot sequence, authentication and provide security service (M3 accessible only)
SoC中的每个物理处理器都有能力在不同的模式下运行,如特权和非特权,安全或不安全。主机的定义超出了物理处理器的范围,也区分了处理器的操作模式。
qemu 启动虚拟机时需要指定Machine 即 -M 参数指定对应的机型.
从我们之前分析的demo看, 默认以virt 启动, 因riscv vcpu 只能运行在S/U mode 下, 所以不需要关注opensbi的部分, 只需要关注u-boot 和 kernel的部分.
这里只说kernel的部分, kernel 在编译时也要按对应的机型编译, 如virt. 还有dtb的部分, kernel 和 qemu 中也是对应的.
新增Machine 只是对于没有开发板时的妥协,便于开发人员在没有开发板时有一个板子的虚拟环境进行测试验证, 所以可以看到该新增Machine的模拟硬件同开发板基本上是一致的;
对于虚拟化来说只有virt就可以了, virt上的feature也是最全的, 最适合跑guest os, 没有必要用其他Machine 跑guest os.
在qemu 中一般会以代码的形式写dtb的相关属性, 可以用 qemu 导出相应机型的dtb信息
1 | qemu-system-riscv64 -machine virt,dumpdtb=virt.dtb -smp 1 -m 2G -nographic |
为了宏观的观察新增一个Machine 需要添加哪些部分, 可以先对比下 virt.dts 和 新增Machine 如sifive_u.dts的内容.
对于dtb 中描述的硬件信息, qemu都需要模拟出来对应的硬件.
qemu 对 libfdt 的接口做了二次封装,部分接口举例如下:
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
TLB是translation lookaside buffer的简称。首先,我们知道MMU的作用是把虚拟地址转换成物理地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统一般都是3~5级。常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。这就像在地图上显示你的家在哪一样,我为了找到你家的地址,先确定你是中国,再确定你是某个省,继续往下某个市,最后找到你家是一样的原理。一级一级找下去。这个过程你也看到了,非常繁琐。如果第一次查到你家的具体位置,我如果记下来你的姓名和你家的地址。下次查找时,是不是只需要跟我说你的姓名是什么,我就直接能够告诉你地址,而不需要一级一级查找。四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。页表查找过程的示例如下图所示。以后有机会详细展开,这里了解下即可。

TLB其实就是一块高速缓存。数据cache缓存地址(虚拟地址或者物理地址)和数据。TLB缓存虚拟地址和其映射的物理地址。TLB根据虚拟地址查找cache,它没得选,只能根据虚拟地址查找。所以TLB是一个虚拟高速缓存。硬件存在TLB后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往TLB确认是否命中cache,如果cache hit直接可以得到物理地址。否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到TLB中。既然TLB是虚拟高速缓存(VIVT),是否存在别名和歧义问题呢?如果存在,软件和硬件是如何配合解决这些问题呢?
虚拟地址映射物理地址的最小单位是4KB。所以TLB其实不需要存储虚拟地址和物理地址的低12位(因为低12位是一样的,根本没必要存储)。另外,我们如果命中cache,肯定是一次性从cache中拿出整个数据。所以虚拟地址不需要offset域。index域是否需要呢?这取决于cache的组织形式。如果是全相连高速缓存。那么就不需要index。如果使用多路组相连高速缓存,依然需要index。下图就是一个四路组相连TLB的例子。现如今64位CPU寻址范围并没有扩大到64位。64位地址空间很大,现如今还用不到那么大。因此硬件为了设计简单或者解决成本,实际虚拟地址位数只使用了一部分。这里以48位地址总线为了例说明。

我先来思考第一个问题,别名是否存在。我们知道PIPT的数据cache不存在别名问题。物理地址是唯一的,一个物理地址一定对应一个数据。但是不同的物理地址可能存储相同的数据。也就是说,物理地址对应数据是一对一关系,反过来是多对一关系。由于TLB的特殊性,存储的是虚拟地址和物理地址的对应关系。因此,对于单个进程来说,同一时间一个虚拟地址对应一个物理地址,一个物理地址可以被多个虚拟地址映射。将PIPT数据cache类比TLB,我们可以知道TLB不存在别名问题。而VIVT Cache存在别名问题,原因是VA需要转换成PA,PA里面才存储着数据。中间多经传一手,所以引入了些问题。

cache控制器是如何判断数据是否在cache中命中呢?所以cache肯定是只能缓存主存中极小一部分数据。我们如何根据地址在有限大小的cache中查找数据呢?现在硬件采取的做法是对地址进行散列(可以理解成地址取模操作)

我们一共有8行cache line,cache line大小是8 Bytes。所以我们可以利用地址低3 bits(如上图地址蓝色部分)用来寻址8 bytes中某一字节,我们称这部分bit组合为offset。
同理,8行cache line,为了覆盖所有行。我们需要3 bits(如上图地址黄色部分)查找某一行,这部分地址部分称之为index
tag array和data array一一对应。每一个cache line都对应唯一一个tag,tag中保存的是整个地址位宽去掉index和offset使用的bit剩余部分(如上图地址绿色部分)。tag、index和offset三者组合就可以唯一确定一个地址了。因此,当我们根据地址中index位找到cache line后,取出当前cache line对应的tag,然后和地址中的tag进行比较,如果相等,这说明cache命中。如果不相等,说明当前cache line存储的是其他地址的数据,这就是cache缺失。

0x00、0x40 地址中index部分是一样的。因此,这2个地址对应的cache line是同一个。所以,当我们访问0x00地址时,cache会缺失
, 然后数据会从主存中加载到cache中第0行cache line;
当我们访问0x40地址时,依然索引到cache中第0行cache line,由于此时cache line中存储的是地址0x00地址对应的数据,所以此时依然会cache缺失。然后从主存中加载0x40地址数据到第一行cache line中
访问0x40地址时,就会把0x00地址缓存的数据替换。这种现象叫做cache颠簸(cache thrashing)
以 sifive fu740 为例
编译opensbi
1 | git clone https://github.com/riscv/opensbi.git |
生成 fw_dynamic.bin
编译uboot 和 spl
1 | cd <U-Boot-dir> |
生成 spl/u-boot-spl.bin 和 u-boot.itb 文件
1 | sudo sgdisk -g --clear -a 1 \ |
sdX 表示通配, sd 卡插到电脑上, sd 卡的节点可能是 sdb sdc 等, 这里以 sdX 表示
1 | sudo apt install tftpd-hpa |
配置完后, tftp 使用的目录为 /srv/tftp
将编出的 work/image.fit 拷贝到该文件夹中
本机测试
1 | tftp localhost |
无错误代表没问题
1 | StarFive # setenv ipaddr 192.168.xx.xx;setenv serverip 192.168.xx.xx |